Imagine asking an AI assistant: “What were the key compliance updates introduced in our company’s cybersecurity policy last quarter?” And within seconds, receiving a precise answer sourced from your latest internal documents, not from outdated training data or public internet content.
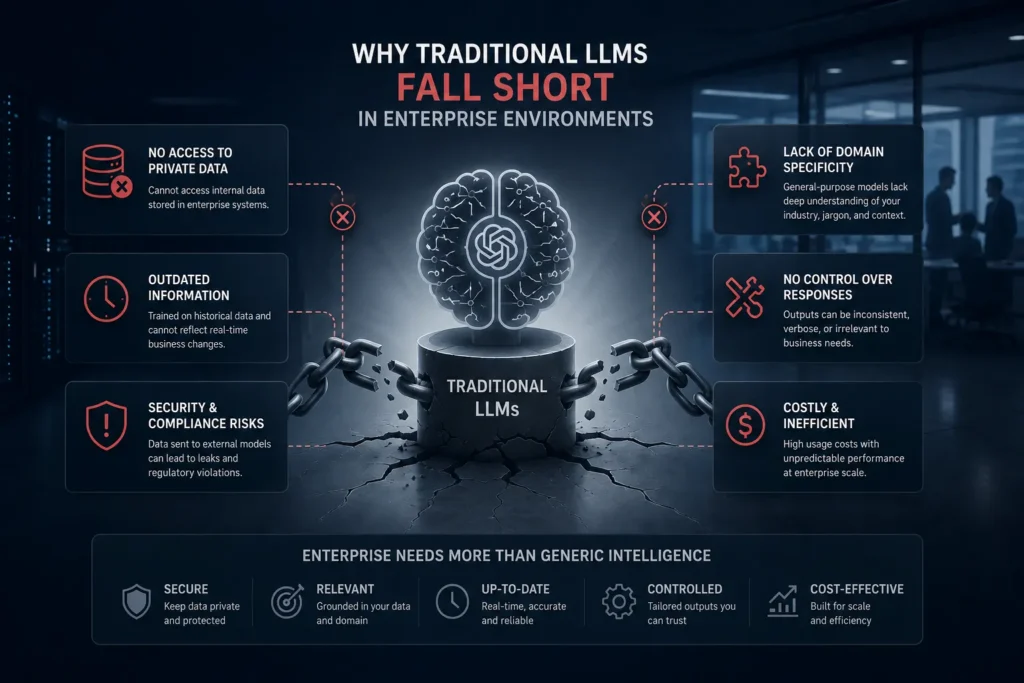
Large Language Models (LLMs) such as GPT, Claude, Gemini, and Llama have unlocked powerful new possibilities for automation, customer support, knowledge management, and decision-making. Yet they share a common limitation: they don’t automatically know what’s happening inside your organization.
Your company policies, customer records, product documentation, contracts, research reports, and internal knowledge are invisible to a standard LLM. This challenge has led to the rapid adoption of RAG architectures for enterprise LLMs, a framework that allows businesses to securely connect their proprietary data to AI systems while maintaining accuracy, governance, and compliance.
In this guide, we’ll break down how enterprise RAG works, why it has become the preferred alternative to fine-tuning, and how organizations can build a scalable Retrieval-Augmented Generation pipeline that delivers trustworthy AI experiences.
Why Traditional LLMs Fall Short in Enterprise Environments?
LLMs are trained on enormous datasets collected during a fixed training period. While they possess broad knowledge, they have no inherent access to:
- Internal company documents
- Real-time business data
- Customer-specific information
- Regulatory updates
- Private knowledge bases
- Enterprise applications
As a result, organizations face several challenges when deploying standalone LLMs:
- Outdated Information: A model may answer based on information learned months or years ago.
- Hallucinations: When the model lacks sufficient context, it may generate plausible but incorrect responses.
- Compliance Risks: Sensitive data cannot simply be uploaded into public AI systems without governance controls.
- Limited Personalization: Generic models cannot answer questions about company-specific processes, products, or policies.
For enterprises, these limitations are significant barriers to AI adoption.
What Is RAG Architecture?
Retrieval-Augmented Generation (RAG) is an AI architecture that combines large language models (LLMs) with external knowledge sources to deliver more accurate, relevant, and up-to-date responses. Instead of relying on information learned during training, a RAG system retrieves information from trusted data sources and uses it to generate answers, helping to reduce hallucinations and improve reliability.
RAG architecture defines how the retrieval layer, knowledge base, and language model work together within a production environment. It determines how information is found, filtered, delivered to the model, and evaluated before a response is generated.
As generative AI adoption continues to grow, RAG has become a core capability for organizations looking to build trustworthy AI applications. According to Gartner, applying RAG in apps will soon become a basic skill for every company using generative AI.
The process looks like this:
User Question → Retrieve Relevant Information → Provide Context to LLM → Generate Accurate Response
This simple idea has transformed enterprise AI because it allows organizations to leverage their existing knowledge assets without retraining models every time information changes.
Why Enterprises Prefer RAG Over Fine-Tuning?
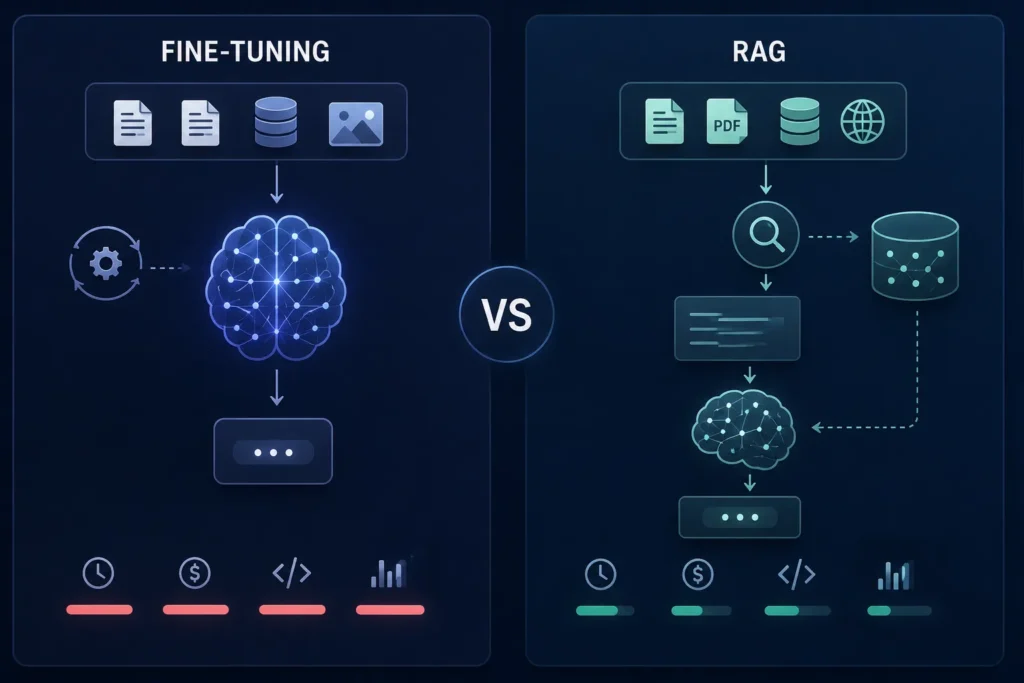
| Aspect | RAG (Retrieval-Augmented Generation) | Fine-Tuning |
|---|---|---|
| Knowledge Updates | Accesses the latest data instantly after indexing. | Requires retraining whenever information changes. |
| Cost | Lower implementation and maintenance costs. | Higher costs due to training and compute resources. |
| Explainability | Provides source citations and document references. | Limited visibility into where information comes from. |
| Deployment Speed | Faster to deploy and update. | Slower due to training and validation cycles. |
| Best Use Case | Enterprise knowledge retrieval and search. | Customizing model behavior, tone, or specialized tasks. |
Benefits of RAG:
- Real-time access to updated information.
- Lower implementation costs.
- Better explainability through source citations.
- improved compliance and governance.
- Faster deployment cycles.
- Reduced hallucination rates.
For most enterprise knowledge use cases, RAG provides greater flexibility and long-term scalability.vides greater flexibility and long-term scalability.
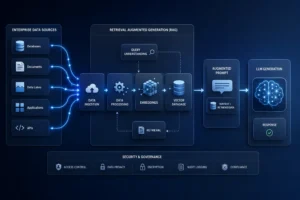
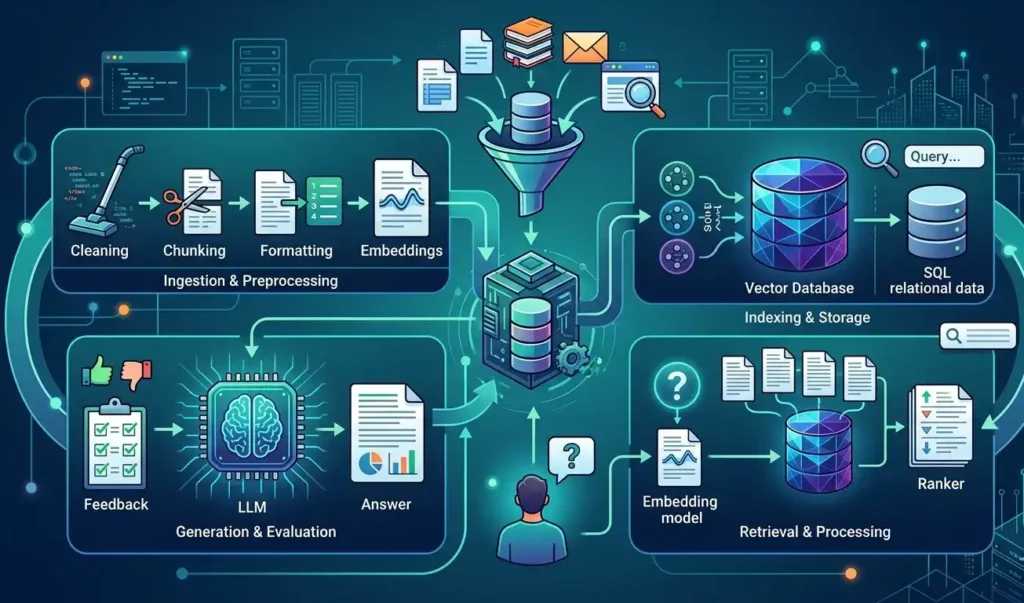
Understanding the Complete RAG Architecture for Enterprise LLM
A production-grade RAG system consists of multiple interconnected layers working together to transform enterprise content into AI-ready knowledge.
Let’s examine each component.
Layer 1: Enterprise Data Sources
Every RAG system begins with data. Enterprise knowledge is typically scattered across numerous platforms, including:
- SharePoint
- Confluence
- Google Drive
- Microsoft Teams
- CRM systems
- ERP applications
- Internal databases
- Customer support platforms
- PDFs and reports
- Legal documents
- Product documentation
The challenge isn’t a lack of information, it is making that information searchable and accessible in a secure way.
This is where data ingestion enters the picture.
Layer 2: Data Ingestion and Processing
Before documents can be retrieved by an AI system, they must be collected, cleaned, and standardized.
The ingestion layer performs tasks such as:
- File extraction
- OCR for scanned documents
- Metadata tagging
- Language detection
- Data cleansing
- Duplicate removal
For example, a 300-page PDF policy document may contain headers, footers, tables, and formatting that provide little value during retrieval. The ingestion pipeline removes unnecessary noise and prepares content for indexing.
Without proper preprocessing, retrieval accuracy can decline significantly.
Layer 3: Document Chunking The Foundation of Effective Retrieval
One of the most overlooked yet critical components of any RAG pipeline are document chunking. Large language models cannot efficiently process entire enterprise repositories or lengthy documents.
Instead, content must be broken into smaller sections known as chunks.
The quality of these chunks directly influences retrieval performance and often leads to:
- Missing context
- Incomplete answers
- Reduced search accuracy
- Higher hallucination rates
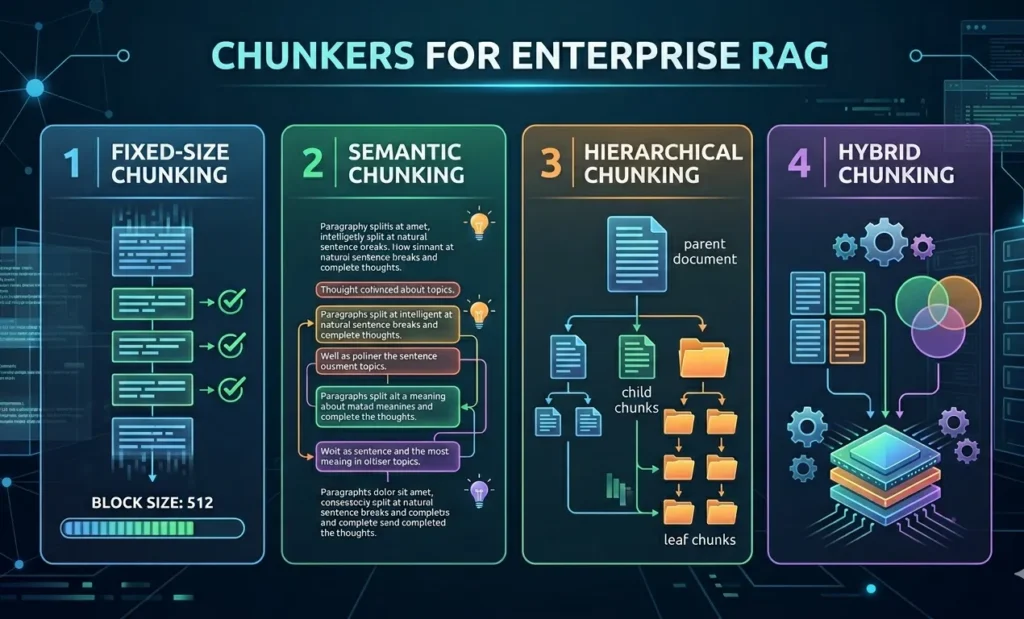
Best Document Chunking Strategies for Enterprise RAG
There is no one-size-fits-all approach to document chunking. The best strategy depends on the type of content, the complexity of the information, and your business goals.
1. Fixed-Size Chunking
Fixed-size chunking divides documents into chunks of a predefined length, such as:
- 500-token chunks
- 100-token overlap
This method is simple, fast, and easy to implement. However, it may split important ideas or context across chunk boundaries, which can affect retrieval accuracy.
2. Semantic Chunking
Semantic chunking groups content based on meaning rather than a fixed length. Documents are typically divided using natural content boundaries such as:
- Headings
- Sections
- Topic changes
By preserving the logical structure of a document, semantic chunking often improves retrieval quality and response relevance.
3. Hierarchical Chunking
Hierarchical chunking organizes content across multiple levels, including:
- Document
- Chapter
- Section
- Paragraph
This approach helps maintain relationships between different parts of a document and is particularly effective for technical documentation, legal records, research papers, and large enterprise knowledge bases.
4. Hybrid Chunking
Many enterprise RAG systems combine semantic and token-based chunking to achieve the best results. This hybrid approach preserves context while maintaining efficient retrieval performance, making it a widely adopted best practice for production environments.
Embeddings: Turning Text into Searchable Knowledge
After the content is divided into smaller chunks, each chunk is converted into an embedding. Embeddings are numerical representations of text that help AI understand the meaning behind words and phrases.
For example, “remote work policy” and “work-from-home guidelines” are written differently but mean almost the same thing. Embedding models can recognize this similarity and place them close together in vector space.
This allows the system to find relevant information based on meaning, not just exact keyword matches, making search results more accurate and useful.
What Makes a Good Vector Database?
A vector database is a core component of any RAG system, responsible for storing embeddings and retrieving relevant information. In enterprise environments, however, basic vector search is not enough. A production-ready vector database should provide the following capabilities:
1. Metadata Filtering
The ability to filter results using metadata helps narrow searches to the most relevant documents. Common filters include:
- Department
- Region
- Security level
- Business unit
This ensures users receive information that matches their specific context and permissions.
2. Hybrid Search
Hybrid search combines semantic search with traditional keyword matching. This approach improves retrieval accuracy, especially when dealing with technical terminology, product names, regulatory requirements, or industry-specific language.
3. Scalability
Enterprise knowledge bases often contain millions of documents and embeddings. A vector database should be able to scale efficiently while maintaining fast query performance and low latency.
4. Security and Access Controls
Document-level permissions should be enforced during retrieval to ensure users can only access information they are authorized to view. This is essential for maintaining security, compliance, and data governance standards.
Popular enterprise vector database solutions include Pinecone, Weaviate, Qdrant, Milvus, Elasticsearch, and pgvector.
5. Reranking: Improving Search Precision
Even the strongest retrieval systems can return multiple relevant results for a single query. However, some results are more useful than others.
Reranking adds a second evaluation step that scores and reorders retrieved chunks based on their relevance to the user’s query. The most valuable content is placed at the top before it is passed to the language model.
A helpful way to think about this process is that retrieval casts a wide net to gather relevant information, while reranking selects the best matches from those results.
By prioritizing the most relevant content, reranking significantly improves search precision and often leads to higher-quality, more accurate responses.
6: Prompt Augmentation: Giving the LLM Context
After retrieval and reranking, the selected content is inserted into the prompt.
The prompt typically contains:
- System instructions
- User query
- Retrieved context
- Response guidelines
At this stage, the LLM finally has access to the information it needs.
Rather than guessing, it generates answers grounded in enterprise knowledge.
Security: The Most Important Layer in Enterprise RAG
For enterprises, AI performance is important. Security is non-negotiable.
A successful RAG architecture for enterprise LLM must ensure that sensitive information remains protected at every stage.
1: Role-Based Access Control
Users should only access information they are authorized to view.
For example:
- Finance teams access financial records
- HR teams access employee policies
- Legal teams access contracts
Permissions must be enforced before retrieval occurs.
2: Encryption
Data should be protected:
- At rest
- In transit
- During processing
Strong encryption reduces the risk of unauthorized access.
3: Audit Trails
Organizations need visibility into:
- Who asked questions
- What documents were retrieved
- What responses were generated
Comprehensive logging supports compliance requirements and internal governance.
4: Sensitive Data Protection
Advanced enterprise systems can automatically detect:
- Personally identifiable information (PII)
- Financial records
- Confidential business information
before content reaches the language model.
Best Practices for Building Enterprise RAG Systems
Organizations that achieve the best results with RAG focus on building a strong retrieval foundation rather than relying solely on the language model.
1: Prioritize Retrieval Quality:
Many AI failures occur because the system retrieves incomplete, outdated, or irrelevant information. Improving retrieval quality often has a greater impact on performance than upgrading the model itself.
2: Improve Content with Metadata:
Adding clear and consistent metadata—such as document type, author, department, date, or topic—helps the system find and rank relevant information more accurately.
3: Use Hybrid Search:
A combination of keyword-based and semantic search typically delivers the most reliable results. Keyword search captures exact matches, while semantic search identifies content with similar meaning.
4: Continuously Evaluate Performance:
Regularly monitor key metrics to identify issues and improve system effectiveness, including:
- Retrieval precision
- Hallucination rates
- User satisfaction
- Source relevance
5: Keep Knowledge Sources Up to Date:
Automate data indexing and synchronization processes to ensure the system always retrieves the latest and most accurate information available.
Final Thoughts:
The success of enterprise AI depends on one critical factor: access to trusted information. A well-designed RAG architecture for enterprise LLM enables organizations to connect proprietary knowledge with modern language models while maintaining security, compliance, and governance.
As organizations continue investing in AI-driven transformation, RAG has emerged as the architectural foundation that turns powerful language models into truly enterprise-ready solutions.
To operationalize this at scale, enterprises need a structured approach that connects architecture, deployment, and business workflows. Techelix’s “LLM Integration” service supports this by enabling smooth integration of RAG systems with enterprise data infrastructure and production LLM environments. It ensures secure, reliable, and scalable AI adoption across the organization.